Migracja z Graphite na Prometheusa wymusiła lepsze poznanie drugiego z nich. Pierwsze podejście do Prometheusa mnie zniechęciło. Niektóre koncepcje wydawały się niepotrzebnie skomplikowane.
W projekcie używamy Victoria Metrics – systemu który jest kompatybilny z zapytaniami Prometheusa (PromQL) z minimalnymi różnicami i dodaje sporo od siebie. Większość materiałów na które trafiałem w sieci dotyczyły Prometheusa dlatego zacznę od zestawienia Graphite z nim a później przejdę do porównania Prometheus z Victoria Metrics.
Zbieranie i przesyłanie metryk
Graphite w konfiguracji z której korzystam agreguje metryki po stronie aplikacji w dropwizard. Wartość Gauge jest wyliczana w momencie publikowania metryk z wykorzystaniem tylko jeden wątku. Więc jeśli ewaluacja wszystkich Gauge trwa dłużej niż minutę (np zapytania do bazy) to skutkowało lukami w metrykach.
Dla prometeusza jest podobnie z tą różnicą że wątki wyliczające wartość Gauga są przydzielane przez serwer http – to zwykła obsługa requestu. Czyli długo trwające pobieranie metryk nie uniemożliwia kolejnego odpytania (które prawdopodobnie też zablokuje zasoby na długi czas).
Instancja usługi z metrykami dla Prometeusza wystawia endpoint z aktualnymi wartościami metryk w tekstowym formacie (można je podejrzeć). Prometeusz pobiera metryki z wszystkich instancji (scrape) co skonfigurowany okres – u mnie co minutę.
Rozsmarowuje te odpytania na całą minutę żeby rozłożyć obciążenie (siebie i sieci). W naszej konfiguracji Prometeusz także liczy percentyle po stronie aplikacji za pomocą micrometera.
Liczenie percentyli po stronie micrometera sprawia że zapytanie jest prostsze i szybsze. Minusem jest to że mamy tylko dostępne skonfigurowane wartości oraz nie możemy robić żadnych sensownych statystycznie operacji na kilku percentylach (może z wyjątkiem max i min). Wynika to z faktu, że tracimy liczebność próbek. Percentyl który powstał na podstawie jednej wartości i percentyl wyliczony z tysiąca są tak samo istotne. To samo dotyczy średnich.
Natywne histogramy Prometeusza nie tracą informacji o liczebności próbek. Dropwizard i StatsD (agregator danych który grupuje requesty do Graphite) mają typ histogramów ale graphite nie ma oddzielnych metod do operowania na nich. Histogram składa się z kilku metryk (jednej dla każdego bucketa). Każdy bucket zlicza wystąpienie wartości z określonego przedziału. Domyślnie bucket ma 12 przedziałów: 0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 0.5, 10, nieskończoność. Ale można je skonfigurować tak żeby odpowiadały interesującym nas przedziałom. Nie korzystałem z nich.
Kolejny minus agregacji po stronie aplikacji to nieoczywisty zakres ich liczenia. Dokładnie wiemy jak daleko patrzą wstecz funkcje Prometeusza takie jak min_over_time, max_over_time i percentyle (quantile_over_time) bo look back window to jeden z elementów zapytania (więcej o tym dalej).
W graphite/dropwizard agregacje dotyczyły okna o stałej wielkości i wadze zmniejszającej się wraz z upływem czasu. To znaczy że dla ruchu (na minutę) większego od wielkości tego okna ignorowaliśmy requesty przy wyliczaniu p99. Zmniejszająca się waga próbki im dalej od jej pobrania sprawia że istotniejsze są te pobrane tuż przed przesłaniem metryk. To pozwala lepiej ocenić aktualny stan aplikacji ale zaburza wynik długotrwałej obserwacji.
Percentyle wyliczane przez micrometera dla Prometeusza wykorzystują HdrHistogram. Okna dla wyliczania to domyślnie 1 minuta ale wartości są grupowane w trzech histogramach po 20 sekund każdy. Rejestrowana wartość jest zapisywana do wszystkich trzech. Przy integracji z histogramem poprzedni jest czyszczony o ile minęło 20 sekund od poprzedniego czyszczenia.
Użycie trzech, według mnie, służy do tego żeby grupować wartości w oknach mniejszych niż 1 minuta, w przeciwnym razie wartość zarejestrowana w 1 sekundzie okna oraz ta z 60 sekundy razem by zostały usunięte w 61 sekundzie (następne okno). Wartość maksymalna jest czyszczona po 3 minutach ( ilość histogramów * wielkość okna (expiry)) co może być błędem (zgłaszane tu i tu) ale sprawia że maksymalna wartość jest bardziej wiarygodna – prawie na pewno trafi do Prometeusza.
Uwzględniając to, że scrapeowanie jest robione co minutę w wielu przypadkach wyliczone p99 nie będzie uwzględniało pełnej minuty – żeby tak było odczyt musiałby być przeprowadzony tuż przed rotacją histogramów. W odczycie zaraz po rotacji dane będą obejmowały tylko ostatnie 40 sekund.
Oba podejścia, w pewnych warunkach, nie uwzględniają wszystkich requestów przy wyliczaniu percentyli. Więc nawet jeśli patrzymy na p999 prawdopodobnie umyka nam więcej niż jeden pomiar na tysiąc. Plusem tego podejścia są łatwiejsze zapytania i mniejsze obciążenie prometeusza.
Zarówno dla Graphite i Prometeusza jeśli instancja padnie przed dostarczeniem metryk przepadają zmiany od poprzedniego przesłania.
Plusy Prometheusa w opisanej konfiguracji
- możemy łatwo podejrzeć wartość metryk (i ciężej wstrzyknąć jakąś bokiem)
- sprawdzamy czy server http instancji działa (ten sam który serwuje produkcyjny ruch), w push sprawdzamy tylko czy instancja jest w stanie wysłać dane
- kilka niezależnych instancji Prometheusa może łatwiej otrzymywać metryki z jednej usługi
- pobieranie metryk różnych instancji rozłożone w czasie
- możliwość wyliczania percentyli po stronie serwera
- wyraźniejsze wskazanie na jakim zakresie danych operuje funkcja
minusy:
- prometheus musi mieć możliwość wykonywania requestów do instancji. Konfiguracje firewalli często umożliwiają ruch na zewnątrz a blokują do wewnątrz
- prometeusz musi być spięty z service discovery (albo mieć zahardcodowaną listę instancji)
- duży ruch i wysycenie puli połączeń przychodzących wyłącza możliwość odczytania metryk. Jeśli zmaleje to metryki zostaną w końcu odczytane chyba że k8s zrestartuje instancje bo ta nie odpowiada na Healthchecka
W sieci prometeusz przedstawia to zestawienie dość stronniczo. W naszej konfiguracji niezawodność dostarczania metryk wydaje się podobna. Tak samo obciążenie sieci i serwera zbierającego metryki. Ale tu powinien wypowiedzieć się ktoś kto utrzymywał oba systemy.
Victoria Metrics oficjalnie wspiera oba modele (push i pull), prometheus wspiera push tylko dla krótko trwających operacji które nie zdążyłyby by być zescrapowane ale są też nieoficjalne projekty które rozszerzają to zastosowanie.
Reprezentacja metryki w zapytaniu
Dla graphite to hierarchiczny string rozdzielony kropkami. Kolejne segmenty zawężają wynik zapytania. Funkcje operujące na segmentach posługują się ich numerem porządkowym liczonym od zera.
Jeśli nie chcemy filtrować żadnego segmentu musimy wpisać tam gwiazdkę. Pisząc zapytanie musimy wiedzieć za co odpowiada dany segment na podstawie dostępnych wartości. Podpowiadanie działa ok ale to trochę toporne zwłaszcza jak mamy dużo gwiazdek albo drzewiastą strukturę gdzie niektóre ścieżki są dłuższe i mają podobne segmenty co już występujące.
Prometheus to robi dużo lepiej: zapytanie to
nazwa_metryki { label = “wartość”, label2!= “innaWartość” }
Funkcje operują na labelach a nie ich indeksach.
Podajemy tylko te labele/segmenty po których chcemy filtrować w dowolnej kolejności.
Wszystkie pozostałe dostaniemy bez potrzeby wpisywania gwiazdek. Nazwa metryki to też label o zastrzeżonej nazwie __name__ więc całe zapytanie możemy zapisać prawie jak JSONa
{__name__= nazwaMetryki, label = “wartość”, label2!= “innaWartość”}
Każda kolejna wartość labela (dowolnego) to nowa metryka ale dokładnie tak samo jest w graphite.
Może z mała różnicą że tam każdy label „pogarszał” zapytanie o kolejną gwiazdkę a tu można dodawać je bez wpływania na czytelność zapytania (ale z jakimś wpływem na utrzymanie klastra 😉 )
Gauge vs Counter
Graphite głównie korzystał z Gauge tzn wartości które mogły maleć lub rosnąć i oznaczały dane agregowane przez ostatnią minutę. Proste do zrozumienia i obsługi ale jeśli wysyłka się nie udała to dane z tej minuty przepadały. W naszych usługach nie widziałem takiej sytuacji prawdopodobnie przez to, że Graphite wysyłał metryki po TCP które ponawia pakiety dla których nie dostanie potwierdzenia odbioru, dodatkowo kod publikujący w przypadku błędu (np zakończenie połączenia z Graphite) odkładał niewysłane metryki i ponawiał ich wysłanie za minutę.
Prometheus zachęca do stosowania Counterów. Czyli wartości które nie mogą się zmniejszyć i agregują się przez cały czas życia instancji. Przykładowa metryka api_seconds_count to counter który podaje łączny czas obsługi requestów, labele pozwalają na pobranie wartości per endpoint, instancja, kod odpowiedzi itp
Wyjątek to restart instancji która zaczyna od zera. W obu przypadkach nie wysłane dane przepadną ale niektóre funkcje prometeusza dodadzą sobie do poprzedniej wartości aktualną. Wykrycie restartu jest robione podczas zapytania które operuje na counterach.
Graphite miał np nonNegativeDerivative która liczyła różnice między kolejnymi wartościami, jeśli to był counter to po restarcie funkcja zwracała 0 co zabezpieczało przed bezsensownymi ujemnymi wartościami ale skutkowało utratą różnicy dla momentu restartu.
Niegubienie danych zawsze na plus ale:
- jeśli bardzo zależy nam na tym żeby móc śledzić każde wystąpienie jakiegoś zdarzenia i minutowa luka w danych jest niedopuszczalna to chyba nie powinniśmy tego robić metrykami (i tak możemy stracić dane)
- to komplikuje zapytania (zaraz do tego wrócę)
Instant Vector vs Range Vector
Jedna z głównych przyczyn porażki mojego pierwszego podejścia do prometeusza.
Instant Vector
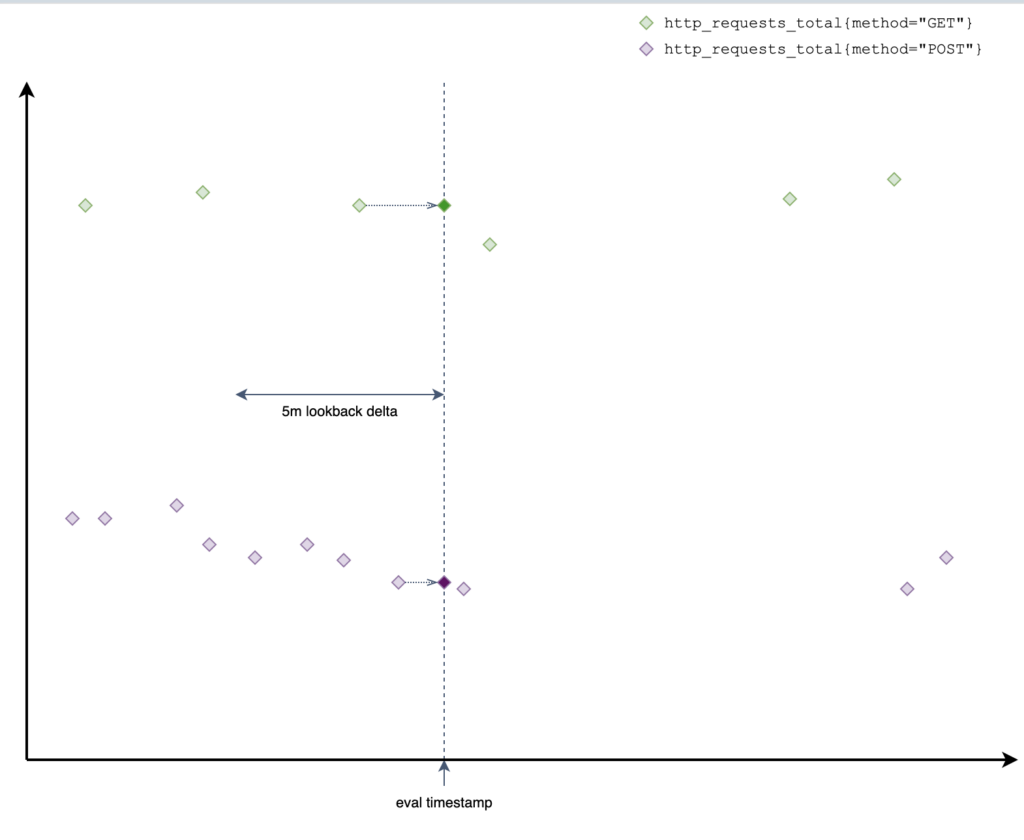
Wynik który zawiera maksymalnie jedną wartość (Sample) per metryka. To najbliższa wartość „przed” podanym timestampem (który nie musi być aktualnym czasem).
Prometheus patrzy 5 minut wstecz jeśli nie znajdzie żadnej wartości to nie zwraca metryki. Ten okres jest konfigurowany globalnie –query.lookback-delta w prometeuszu oraz -search.maxLookback w VMa. Według mnie ten czas powinien być powiązany okresem odczytu, który może różnić się per metryka więc prawdopodobnie sensownie opierać się na największym z interwałów.
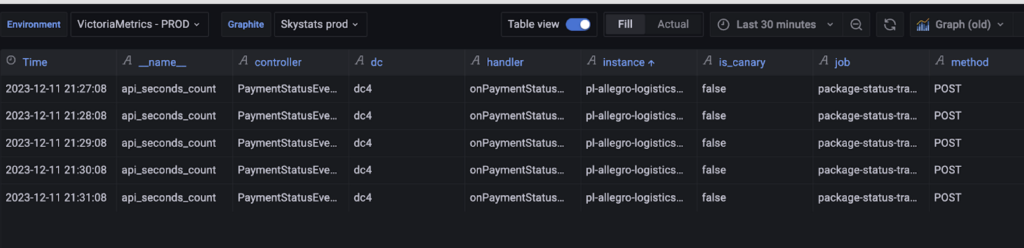
Tabelaryczny podgląd próbek bezpośrednio w prometeuszu pokazuje odczyty wraz z timestampami (po @).
Grafana też na to pozwala ale trzeba zaznaczyć Table view na górnej belce, Format Table i Instant na dolnej. Ale jak już się uda to przedstawia czytelniej timestampy i umożliwia sortowanie.
Range Vector
Jak wyżej ale konfigurujemy okno samemu w nawiasach kwadratowych i zwracane są wszystkie sample a nie tylko ostatni.
Prometheus typuje wyrażenia więc jeśli Range Vector ma tylko jedną wartość to nie czyni go Instant Vectorem
W dokumentacji Prometheusa kilkukrotnie pada że przedstawiać na wykresie można tylko Instant Vector, rysowanie Range Vectora jest niemożliwe/niezdefiniowane. Internet powtarza to jak mantrę ale dla mnie jest dokładnie odwrotnie: Z jednej wartości nie zrobimy wykresu ale z listy wartości razem z timestampami jak najbardziej. To o czym Internet nie wspomina tak często to fakt że prometheus wystawia dwa endpointy do zapytań. Nawet dokumentacja prometeusza wspomina o tym daleko od stwierdzeń co może być rysowane.
query (Instant query)
Wbrew pozorom nie musi zwracać Instant Vectora… Znaczy tylko tyle że zapytanie będzie ewaluowane tylko dla jednego momentu w czasie (Instanta).
Vector jest oznaczany w odpowiedzi jako typ Vector, Range Vector jest zwracany jako matrix…
Request składa się z query i timestampa który można pominąć i prometeusz ustawi go na aktualny czas. Zaznaczenie w Grafanie Instant query korzysta z tego endpointu.
query_range (Range query)
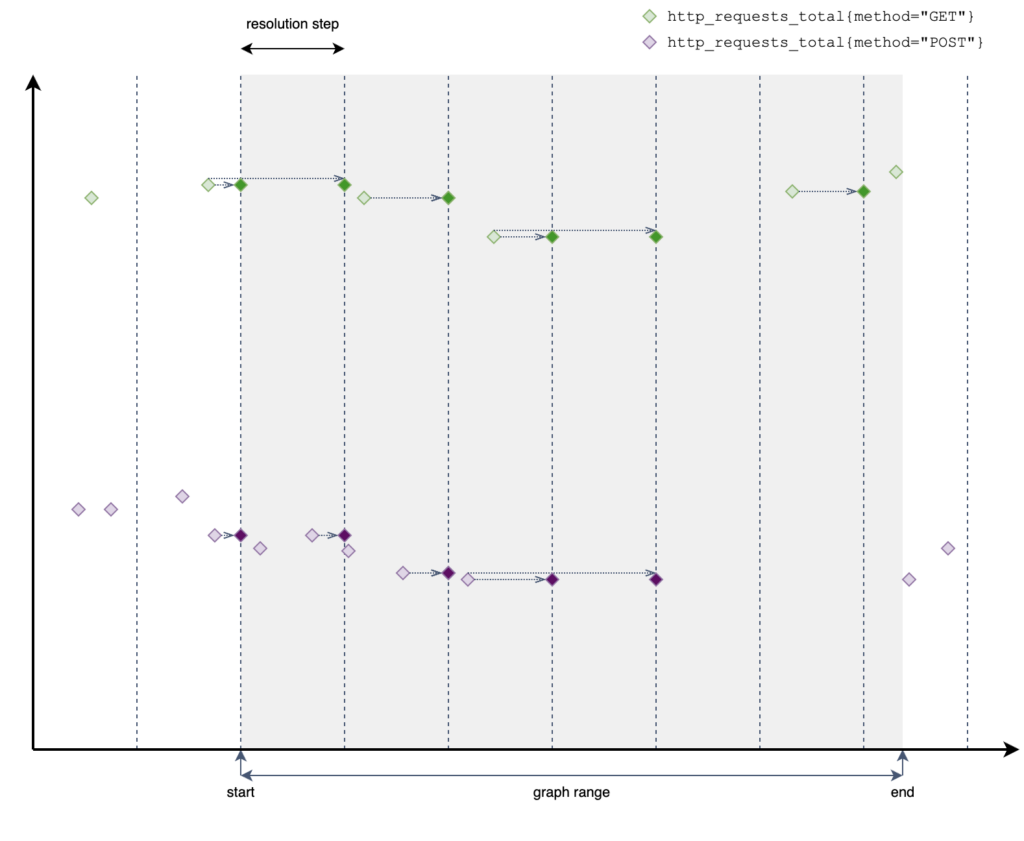
Request wykonywany podczas rysowania wykresu. Składa się z zapytania, czas początku, końca oraz step/interval. Ostatni parametr jest ustawiany automatycznie przez Grafanę w zależności od tego jak szeroki wybrano przedział czasu ale można na nie wpłynąć ręcznie. Zapytanie jest wykonywane wielokrotnie do narysowania jednego wykresu (robiony jest tylko jeden request). Rezultat musi w wyniku zwracać Instant Vector (czyli „odwrotnie” niż sugeruje nazwa zapytania). Jeden punkt dla jednej ewaluacji. Czas początku i końca nie ogranicza pobieranych danych. Pierwsza ewaluacja odbywa się dla początku zakresu ale w zapytaniu może być pobierany dowolnie duży Range Vector(!)
Zakres resolution step z ilustracji poniżej to nie to samo co zakres Range Vectora, ale powinny być ze sobą powiązane o tym później.
Instant Vector – wiele metryk każda po jednej wartości
Range Vector – wiele metryk wiele wartości
Instant query – jedno wykonane zapytanie o dowolnym rezultacie. Do wszystkiego poza wykresami
Range query – zapytanie wykonane wielokrotnie każde o rezultacie Instant Vector. Tylko do wykresów
Czy to nie wygląda jak przypadkowa złożoność? To według mnie dobry przykład czemu dobre nazewnictwo i abstrakcje są istotne.
Pod spodem oba wykonuje ta sama metoda tylko z innymi parametrami (instant ustawia timestamp jako start oraz koniec i ustawia range na 0).
Jakie są skutki powyższych rozwiązań z perspektywy użytkownika?
- Każdy metryka typu counter musi występować z funkcją która zrobi z niej coś użytecznego (rate, increase i podobne)
- poza początkiem i końcem zakresu (prawy górny róg grafany) oraz częstotliwością scrapeowania musisz ZAWSZE zastanowić się nad wielkością okna w Range Vectorze. Wielkość tego okna powinna zależeć od wybranego zakresu dat (jak jest duży) a konkretnie być powiązana z parametrem step/interval.
Jeśli będzie za mały to zignorujemy dane i będziemy mieli fałszywy obraz. Jeśli będzie za duży to nie będziemy widzieli krótko trwających problemów bo zostaną uśrednione. Jeśli będzie w sam raz to zoom in/out to popsuje (zmieni step).
Żeby increase (zmiana wartości – więcej o funkcjach niżej) działał dobrze potrzebuje przynajmniej 2 sampli w oknie.
Range nie może być równy wartości step bo wtedy okno będzie miało max 1 wartość. Nie może być równy 2x step ponieważ scrape interval nie jest przestrzegany idealnie. Czasem metryki będą odczytane trochę wcześniej a czasem trochę później i mogą się ułożyć tak że w okresie 2x step będzie tylko jedna wartość.
Jeśli to będzie 3x step to brak jednego sampla i przesunięcie drugiego będzie skutkowało tylko 1 samplem w oknie…
Prometheus nie daje możliwości ustawiania okna w zależności od stepu. Taką możliwość daje grafana. Twórcy wychodzą z założenia że powyższe problemy dotyczą tylko rysowania wykresów więc soft od wykresów powinien się tym zajmować.
Jeden z twórców Prometheusa pracuje dla Grafany i dodaje funkcje które według mnie są obejściem niedoskonałości Prometeusza. Zmienna $__interval daje dostęp do stepu z jakim rysowany jest wykres ale prometheus nie obsługuje działań arytmetycznych w oknie [5 * $__inverval] nie przejdzie więc dodali jeszcze
zmienną $__rate_interval oparta o scrape_interval i step żeby zaadresować powyższe problemy:
The value of $__rate_interval is defined as max($__interval + Scrape interval, 4 * Scrape interval), where Scrape interval is the “Min step” setting (also known as query*interval, a setting per PromQL query) if any is set. Otherwise, Grafana uses the Prometheus data source’s “Scrape interval” setting.
- step niższy niż scrape interval skutkuje zwróceniem (i wyświetleniem) wielu „sztucznych” punktów. Które są wielokrotnie powtórzoną wartością ostatniego sampla. Trudniej w takiej sytuacji oddzielić rzeczywiste odczyty od ich powtórzeń. Zwłaszcza jeśli wartość metryki się nie zmieniła. W graphite podobnie działa funkcja keepLastValue ale można jej nie używać, mieć luki w danych i tylko rzeczywiste sample
- jeśli koniec okna nie pokrywa się z samplem to funkcje takie jak rate i increase estymują wartości na końcu okna na podstawie późniejszych wartości (więcej o tym dalej)
- dla odmiany na plus: jest jasne jak szerokiego zakresu dotyczą wartości min_over_time, max_over_time i percentyle tj quantile_over_time (bo sami je podajemy)
Graphite keeps it simple
Graphite robi to prościej: pobiera wszystkie sample od startu do początku zadanego zakresu. Jeśli chcemy poznać różnicę między kolejnymi wartościami to funkcja derivative patrzy na następny/poprzedni punkt bez koncepcji okna i niezależnie od tego jak daleko te punkty są od siebie.
Niektóre funkcje zapewniają agregacje w oknach np summarize który przyjmuje wielkość okna i funkcję agregującą. Ale graphite nie wymusza wykonywania agregacji żeby policzyć RPSy czy zmiany wartości licznika. Nie ma Instant/Range Vectorów są tylko listy wartości.
Operacje na metrykach
Funkcje operujące w poziomie lub pionie. Nie ma w PromQL takich które działają w obu płaszczyznach. Warto rzucić okiem na to zestawienie.
W poziomie/na jednej metryce – Victoria Metrics mówi o takich funkcjach „rollup” –
Liczniki:
increase – różnica między początkiem a końcem okna, uwzględnia reset licznika
rate – increase podzielony przez wielkość okna czyli przyrost na sekundę, uwzględnia reset
irate – rate który patrzy tylko na dwie ostatnie próbki (nawet jeśli okno jest dużo większe), uwzględnia reset. Teoretycznie służy do przedstawiania szybko zmieniających się wartości co lepiej pokaże ich zmienność (bez uśredniania). W praktyce oznacza że większość danych jest ignorowana a rezultat zależy od tego które próbki będą dwoma ostatnimi w oknie.
changes – ile razy się zmieniła wartość
resets – ile razy miał miejsce reset licznika
<aggregation>_over_time
avg_over_time, max_over_time, quantile_over_time, count_over_time
Funkcje patrzą na wszystkie wartości w oknie i na ich podstawie obliczają średnią, maksymalną wartość, zadany percentyl lub liczą ile razy występuje każda z wartości
Gauge:
delta – różnica między wartością z końca i początku okna
idelta – różnica między dwoma ostatnimi wartościami okna
deriv – rate dla gaugy
Zmiana wartości otrzymanej w powyższych funkcjach (wg VictoriaMetrics Transformation functions)
np. abs, ceil, histogram_quantile, label_replace, log10, round, sqrt
Niektóre funkcje w pionie/agregujące pojedyncze wartości różnych metryk. Wg prometheusa to operatory agregacji:
- stddev (odchylenie standardowe)
- count_values – odpowiednik count_over_time
- topk(k) – zwrócenie tylko k pierwszych metryk, analogicznie bottomk
Kolejność tego opisu odpowiada kolejności zapisu i wykonania operacji w PromQL
- transformacja [ Instant Vector ]
- agregacja [ Instant Vector ]
To zakłada że nie można zrobić transformacji na Range Vectorze nawet jeśli taka operacja miałaby sens. Część agregacji ma swoje odpowiedniki w Rollupach tyle że z suffixem _over_time.
max_over_time zwróci największą wartość z okna jednej metryki (poziom) a max zwróci wartość największej metryki (pionowo).
Istnienie oddzielnego endpointu query_range który udaje że jest do czegoś więcej niż grafów sugeruje że będzie można powyższą kolejność powtórzyć kilkukrotnie (co step) a później zagregować wyniki każdego ze stepu (które są instant vectorami więc typy się zgadzają). Ale tak nie jest i nie da się tego zrobić w ten sposób. Do wersji 2.7 można było osiągnąć ten efekt tylko przez zastosowanie rules czyli zapytań które generują metryki na podstawie innych metryk. Coś w stylu widoku w bazach danych tylko obliczanego w momencie dostarczania danych. Po wersji 2.7 doszły jeszcze podzapytania.
Podzapytania
Jeśli chcemy wielokrotnie wykonać jakieś zapytanie (dla różnego czasu) a następnie zagregować wyniku to mamy do tego dodatkową składnie
increase(prometheus_http_requests_total[5m])[1h:5m]
Ten dodatkowy nawias kwadratowy oznacza: wykonuj te zapytanie ze stepem 5m cofając się o godzinę. Czyli dokładnie to co robi range_query. Range query nie potrafi zrobić nic innego z tymi danymi (jest w końcu tylko do rysowania) a podzapytania mogą np wybrać największą wartość
max_over_time(increase(prometheus_http_requests_total[5m])[1h:5m])
Można nie podawać stepu [1h:] będzie wtedy równy default evaluation interval propertiesowi określającemu jak często wykonywane są zapytania odpowiedzialne za wykonywanie rules (tych widoków). Domyślnie 15s.
Podobnie jak przy range_query z niepasującym step tak samo podzapytania z zakresem niepodzielnym przez step skróci zakres, [10m:6m]
Graphite keeps it simple again
Graphite również ma oddzielne funkcje dt jednej metryki i kilku metryk. Ale wynik funkcji to dla niego po prostu liczba lub kilka liczb. Można je komponować w dowolnych konfiguracjach.
Wszystko jest realizowane przez funkcje – okna jak w Range Vector także np
summarize(nonNegativeDerivative(groupByNodes(stats.tech.obfuscated.consumer.*.status.obfuscated.*.package-status-tracker.2xx.20{0,1}.count, 'sumSeries', 7)), "1h", "sum", true)
Metryka to ilość odpowiedzi 200 i 201 zwróconych szynie danych przez usługę package-status-tracker zsumowanych według wszystkich segmentów poza 7 czyli nazwą eventu. Następnie funkcja nonNegativeDerivative wyznacza różnice między kolejnymi wartościami tak increase w PromQL ale z nieco gorszym wsparciem dla resetu. Graphite nie interesuje jak odległe są od siebie kolejne wartości. Najbardziej zewnętrzna funkcja sumuje te przyrosty w godzinne okna. Wszystkie pośrednie etapy przetwarzania mają ten sam typ.
Rate i Increase
Increase mówi o ile licznik zwiększył się w zadanym czasie, w naszych serwisach najczęściej sprawdzamy przyrost z ostatniej minuty (co tyle jest scrape). Rate analogicznie podaje przyrost na sekundę i chyba najczęstsze wykorzystanie to wyliczanie RPSów. Ta funkcja uwzględnia resety licznika. Tzn w czasie przetwarzania zapytania sprawdza wszystkie kolejne pary punktów i jeśli wykryje że kolejny jest mniejszy to do wyniku dodaje wartość poprzedniego.
Jeśli pierwsza i ostatnia wartość w oknie (te które są wykorzystywane do wyliczania rate i increase) są odległe od granicy okna o mniej niż 110% średniej odległości między samplami to prometeusz robi ekstrapolacje (zakłada że obserwowany przyrost będzie się zachowywał tak samo na granicy okna).
Nie widziałem żadnych optymalizacji minimalizujących pobierane punkty czyli prawdopodobnie nawet jeśli wybierzemy bardzo duże okno to znaczenie mają tylko dwie wartości.
Zwłaszcza przy increase to może być nieoczywiste czemu wartości całkowite czasem mają ułamkowe przyrosty. Według mnie wynika to z przerzucenia na użytkownika konieczności ustalania okna, twórcy zapewniają że taki ułamkowy increase dalej jest statystycznie prawdziwy.
Twórcy VM uznali że aproksymowanie danych które już mamy jest bez sensu i jeśli w oknie nie zmieściła się jakaś wartość to VM patrzy nieco wstecz żeby ją pobrać. Nawet jeśli i tak jej nie znajdzie to nie jest robiona żadna aproksymacja.
W prometeuszu jest jeszcze funkcja irate wg dokumentacji
irate should only be used when graphing volatile, fast-moving counters
Zmiany w stosunku do rate są dwie: nie ma żadnych aproksymacji, ale brane są tylko dwa ostatnie sample. Co dodatkowo komplikuje zależność między step a wielkością okna. Możemy dobrać odpowiednie wartości (albo skorzystać ze zmiennych Grafany), później każdy step może pobierać dane z ogromnego okna po to żeby skorzystać tylko z 2 ostatnich punktów. Pozostałe mogłyby nie istnieć.
Filtry
Filtry usuwają wartości które go nie spełniają.
api_seconds{service="package-status-tracker", quantile="0.99"} > 0.1
Pozostawi tylko metryki większe niż 100 ms (metryka jest w sekundach).
Dodanie Bool po operatorze zmienia zachowanie – po filtrowaniu pozostaną wszystkie metryki, te które spełniają warunek otrzymują wartość 1 pozostałe 0. Przydatne np przy takim zapytaniu
avg(api_seconds{service="package-status-tracker", quantile="0.99"} > bool 0.01)
które zwróci proporcje próbek spełniających warunek do wszystkich.
Graphite ma mniej wygodne rozwiązanie – funkcje. Np filterSeries, grep, threshold, removeBetweenPercentile.
filterSeries(system.interface.eth*.packetsSent, 'max', '>', 1000)
Z drugiej strony ma też filtry które operują nie na seriach tylko poszczególnych samplach removeBelow/AboveValue (a później można wywołać funkcję która działa na całych seriach)
Vector matching
Gdzie chodzi tylko o Instant Vector (oczywiście duh…)
Jeśli chcemy wartość wszystkich metryk przemnożyć/odjąć/dodać… do stałej to zapis jest oczywisty metryka * 3. Po takiej operacji przepadnie nazwa metryki ale labele zostaną a wartość będzie odpowiednio zmieniona
Możemy robić te arytmetyczne operacje na dwóch Instant Vectorach ale muszą mieć dokładnie takie same labele (nazwa metryki może być różna). Jeśli metryka po lewej nie ma pary to jest odfiltrowana. Jeśli chcemy zezwolić na operację mimo różnic w labelach to musimy skorzystać z on (lista labeli które muszą się zgadzać) ignore (lista label które mogą się różnić)
Jeśli jedna metryka po lewej „pasuje” do kilku po prawej to musimy użyć group_left żeby potwierdzić że to zamierzone. Jest też group right a obie mogą przyjmować listę labeli które mają być skopiowane do lewej metryki.
Graphite ma do tego metodę applyByNode
applyByNode(stats.counts.haproxy.*.*XX, 3, "asPercent(%.5XX, sumSeries(%.*XX))", "%.pct_5XX")
nigdy jej nie używałem. W prometeuszu ta operacja wydaje się czytelniejsza.
Set operators
Prometheus nazywa to operacjami na zbiorach ale można to rozumieć jako instrukcje warunkowe
- zapytanie and drugie_zapytanie: wyświetla metryki które są wynikiem pierwszego zapytania o ile mają odpowiednik o dokładnie takich samych labelach w drugim (nazwa drugiej metryki i wartość jest nieistotna)
- zapytanie or drugie_zapytanie: robi to co and ale wyświetla wyniki drugiego_zapytania bez pary
- zapytanie unless drugie_zapytanie: wyświetla tylko wynik zapytania bez pary
Nie używałem, tego typu funkcje są potrzebne raczej tylko w czujkach a nasz system do czujek ma swoje odpowiedniki
Grafana
Dla graphite pozwala na odniesienia do kolejnych zapytań przez #A #B itd. To pozwala na rozbicie skomplikowanego zapytania na mniejsze i czytelniejsze części. Prometeusz niestety tego nie ma ale VM ma możliwość przypisywania zapytań do zmiennych w wyrażeniach WITH
Prometheus ma zmienne i parametry nieobecne dla graphite:
- __range: wielkość zakresu wybranego w prawym górym rogu grafany w sekundach
- __rate_interval: wartość większa niż rate (opisana wcześniej) dla bardziej odpornego na braki w metrykach obliczania rate/increase
Legend format – przez odniesienia {{nazwa_labela}}.{{inny_label}} pozwala na modyfikowanie jak ma być wyświetlana metryka bez stosowania funkcji operujących na labelach
Min step – do wpływania na parametr step. Według mnie niepotrzebne poza debugiem i próbą zrozumienia jak działa zapytanie
Resolution – też wpływa na step, pozwala go ustawić na mniejszą wartość niż sugeruje wybrany zakres
Format – time series/table/heatmap nie wiem czemu Grafana wymaga wybrania przy zapytaniu atrybutu który dotyczy prezentacji i powinien być ustawiany tylko przez Visualisation
Instant – wysyła request do endpointu query
Exemplars – możliwość korelacji metryk z logami. Nie znam szczegółów – nie mamy takiej opcji
Zmiany w Victoria Metrics
Pełna lista zmian TUTAJ. Najważniejsze według mnie:
- VM nie robi aproksymacji przy rate/increase i innnych funkcjach które liczą różnicę między próbkami, pobiera trochę więcej danych i bazuje na nich. Konkretnie patrzy wstecz 5 minut i jeszcze odejmuje step lub window (w zależności co jest większe). Dlatego dzięki VM nie widzimy ułamkowych wartości increase dla liczników z wartościami całkowitymi
- ma wbudowaną analizę zapytania (trzeba wybrać trace query)
- stara się unikać nazewnictwa Instant/Range Vector, skupia się na rollup/transform/aggregate
- pozwala odnosić się w zapytaniu do wartości step. Grafana też na to pozwala ale nie wszystkie zapytania odbywają się przez nią
- pozwala pomijać wielkość okna i podawanie funkcji rollup. Co stara się zdjąć z użytkownika konieczność znania szczegółów PromQL. Nie jestem pewny czy nie idzie z tym zbyt daleko.
Trzeba pamiętać, że jeśli zapytania przechodzą przez proxy które je parsują (np promxy) to dostępność nowych funkcji zależy od tego czy proxy wspiera MetricsQL.













{kind=link}
{kind=link}